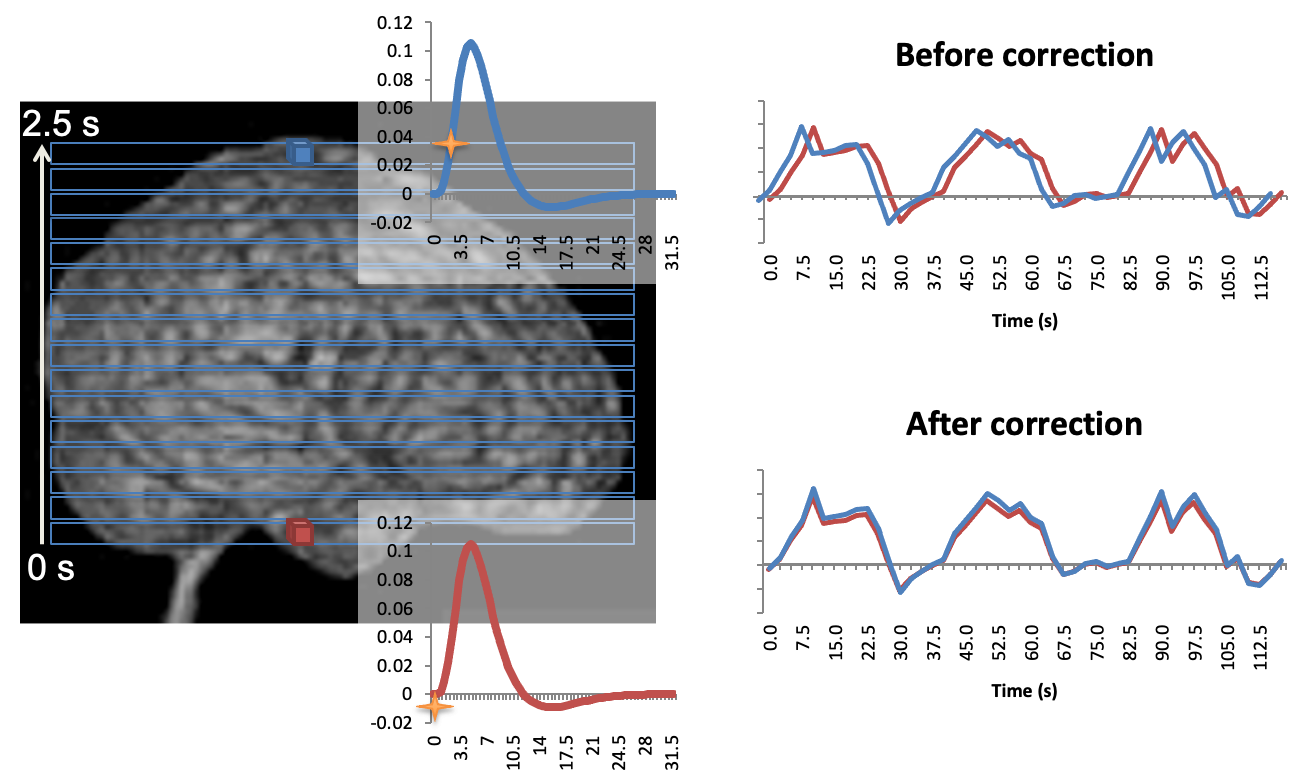
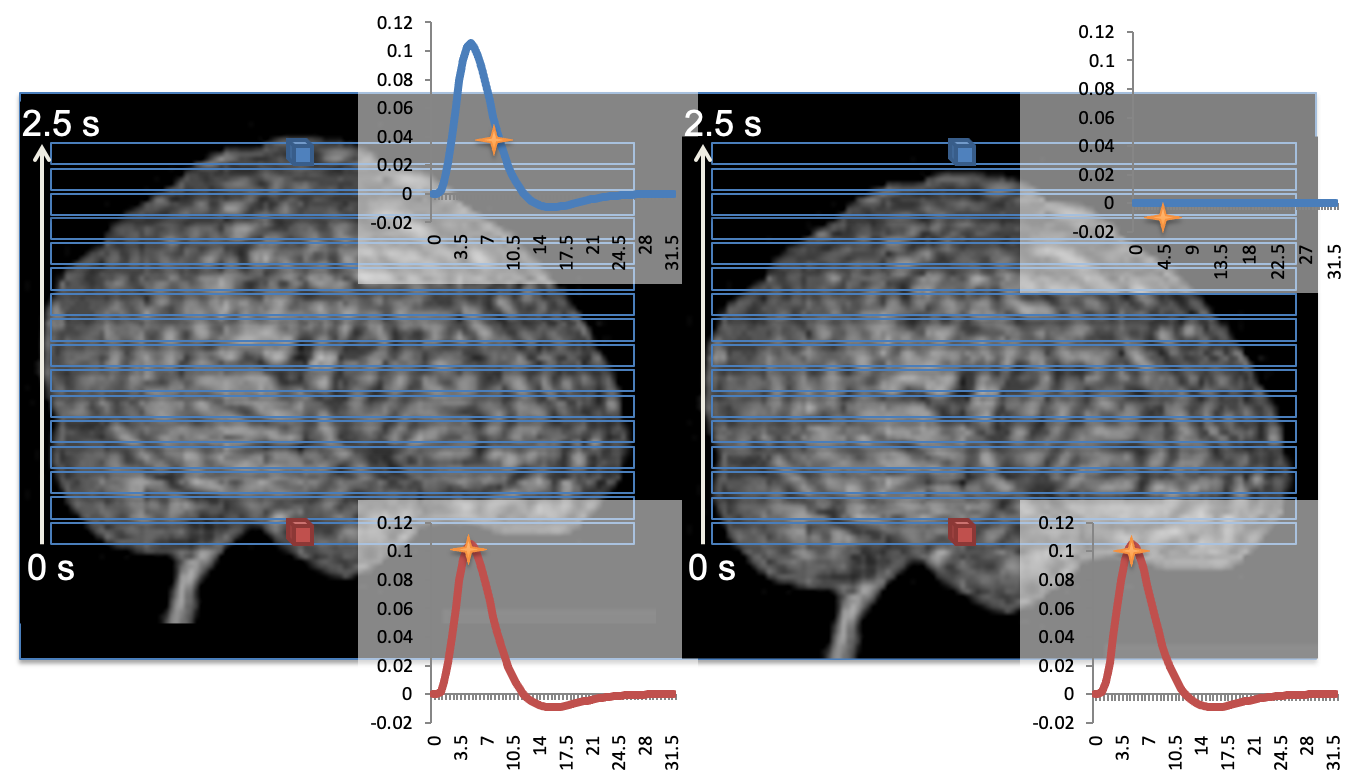
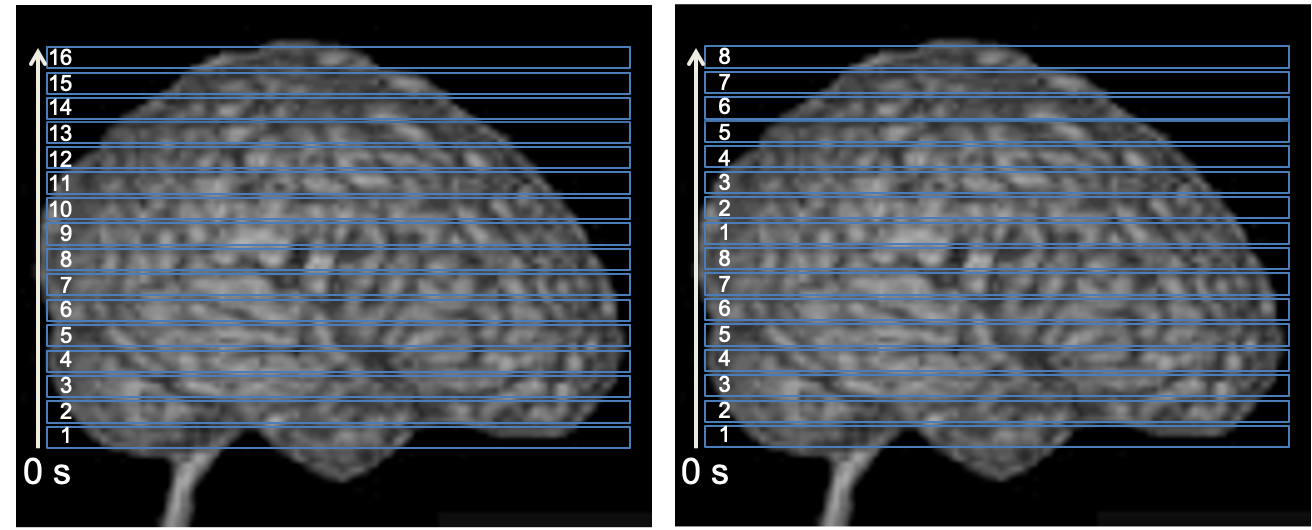
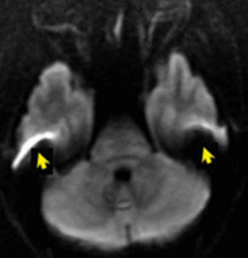
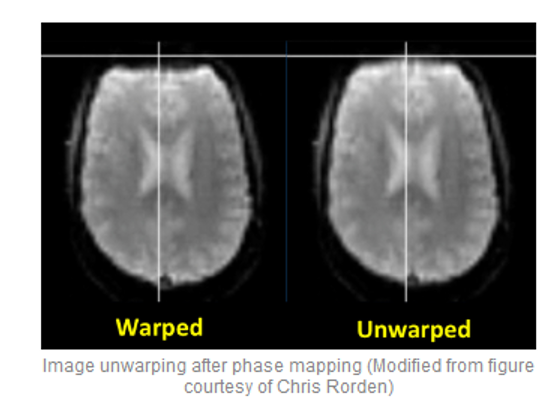
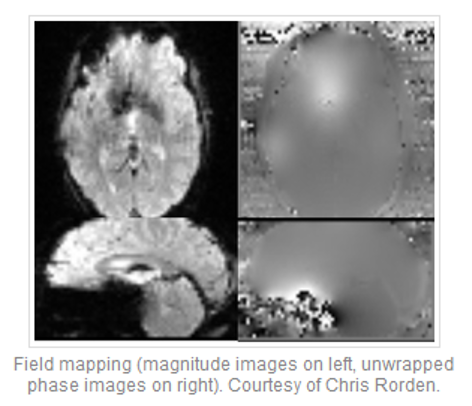
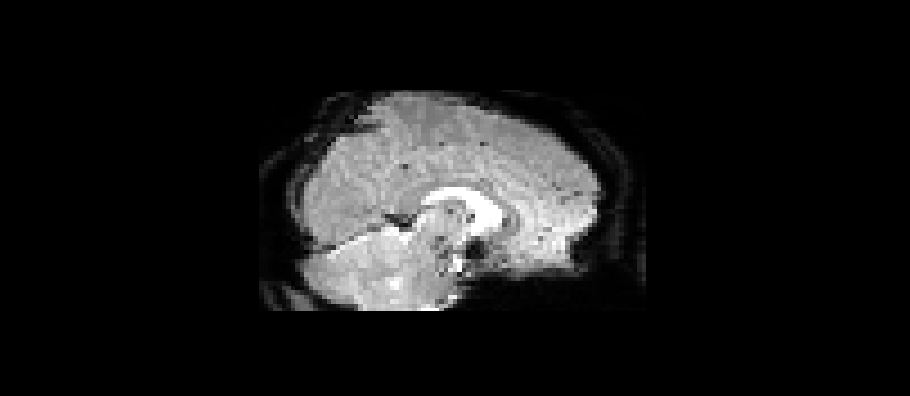
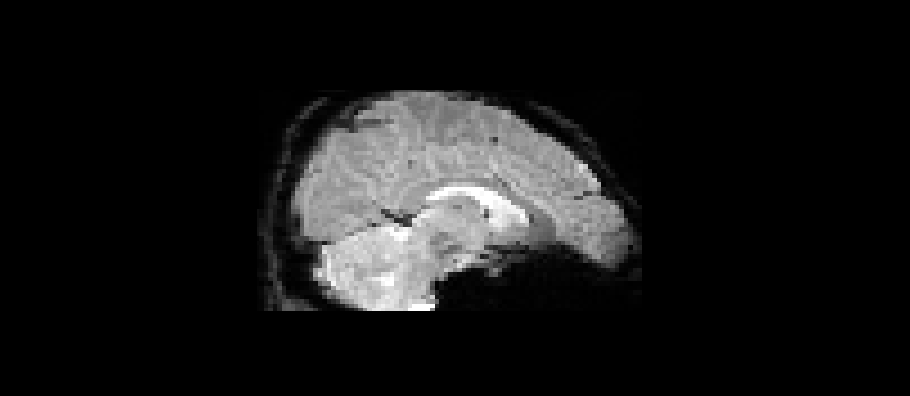
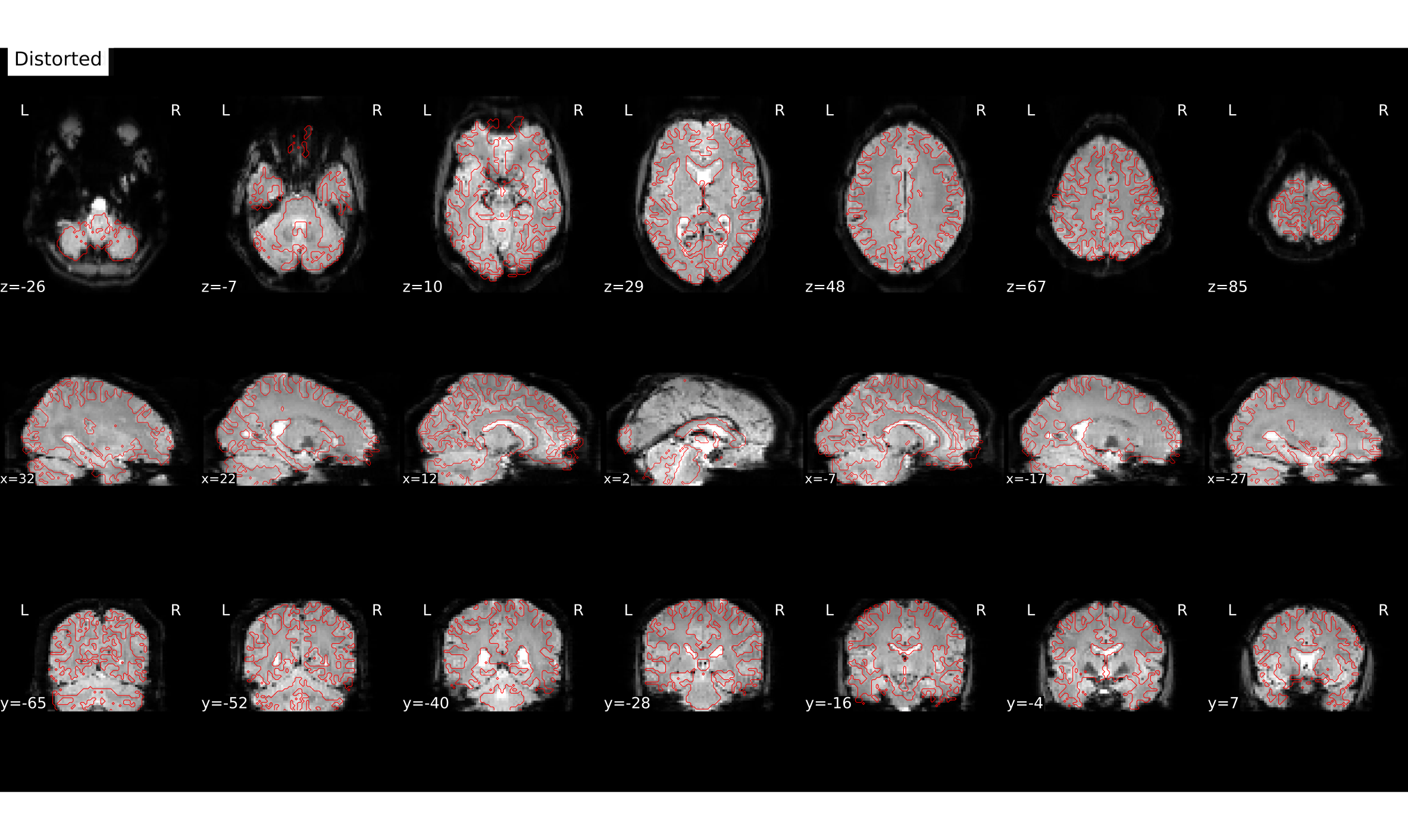
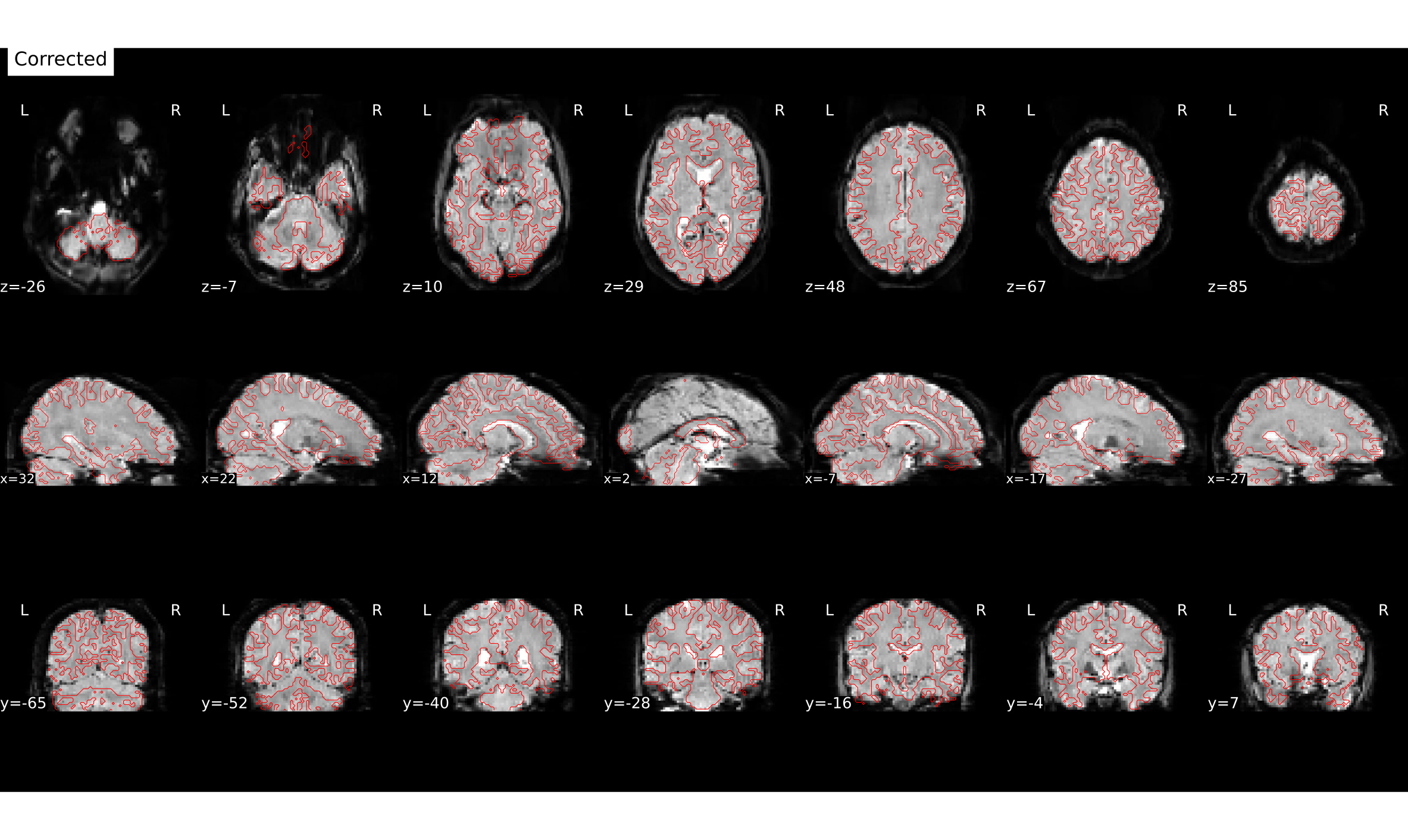
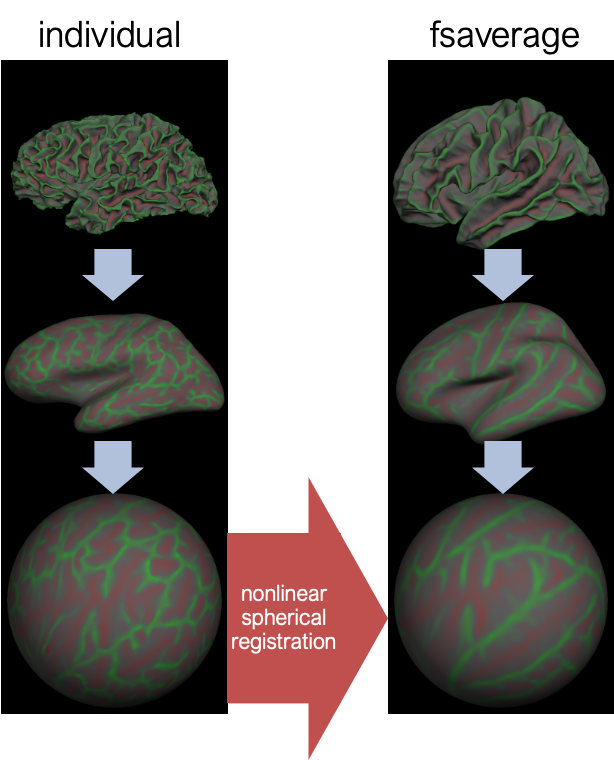
# source: chatgpt
import numpy as np
import matplotlib.pyplot as plt
from scipy.ndimage import shift
from sklearn.metrics import mutual_info_score
def create_realistic_fish(size=100):
img = np.zeros((size, size))
cx, cy = size // 2, size // 2
# Draw backbone (slight curve)
for x in range(20, 80):
y = int(cy + 5 * np.sin((x - 20) / 60 * np.pi)) # slight wave
img[x, y] = 1
# Draw ribs (angled lines)
for x in range(25, 75, 5):
y = int(cy + 5 * np.sin((x - 20) / 60 * np.pi))
for dy in range(1, 8):
if 0 <= y - dy < size:
img[x, y - dy] = 1
if 0 <= y + dy < size:
img[x, y + dy] = 1
# Draw head (big circle)
for i in range(-10, 11):
for j in range(-10, 11):
if i**2 + j**2 < 100:
xi = 20 + i
yj = cy + j
if 0 <= xi < size and 0 <= yj < size:
img[xi, yj] = 1
# Draw eye (small dot)
img[17, cy + 5] = 0 # black eye (making a small black pixel inside head)
# Draw tail fin (V shape)
for d in range(10):
x1, y1 = 80 + d, cy - d
x2, y2 = 80 + d, cy + d
if 0 <= x1 < size and 0 <= y1 < size:
img[x1, y1] = 1
if 0 <= x2 < size and 0 <= y2 < size:
img[x2, y2] = 1
# Draw dorsal (top) fin
for d in range(10):
x, y = 40 - d//2, cy - 12 - d
if 0 <= x < size and 0 <= y < size:
img[x, y] = 1
# Draw ventral (bottom) fin
for d in range(10):
x, y = 60 + d//2, cy - 12 - d
if 0 <= x < size and 0 <= y < size:
img[x, y] = 1
return img
# Create fixed image (realistic fish skeleton)
fixed = create_realistic_fish()
# Create moving image with inverted contrast
moving = 1 - fixed
# Introduce a misalignment
def shift_image(img, dx, dy):
return shift(img, shift=(dx, dy), mode='constant', cval=0)
moving_misaligned = shift_image(moving, 4, 5)
# Define mutual information computation
def compute_mi(img1, img2, bins=32):
img1_flat = img1.ravel()
img2_flat = img2.ravel()
c_xy = np.histogram2d(img1_flat, img2_flat, bins=bins)[0]
mi = mutual_info_score(None, None, contingency=c_xy)
return mi
# Search for best alignment by shifting
dx_range = np.arange(-10, 11)
dy_range = np.arange(-10, 11)
mi_matrix = np.zeros((len(dx_range), len(dy_range)))
for i, dx in enumerate(dx_range):
for j, dy in enumerate(dy_range):
shifted = shift_image(moving_misaligned, dx, dy)
mi_matrix[i, j] = compute_mi(fixed, shifted)
# Find best shift
best_idx = np.unravel_index(np.argmax(mi_matrix), mi_matrix.shape)
best_dx = dx_range[best_idx[0]]
best_dy = dy_range[best_idx[1]]
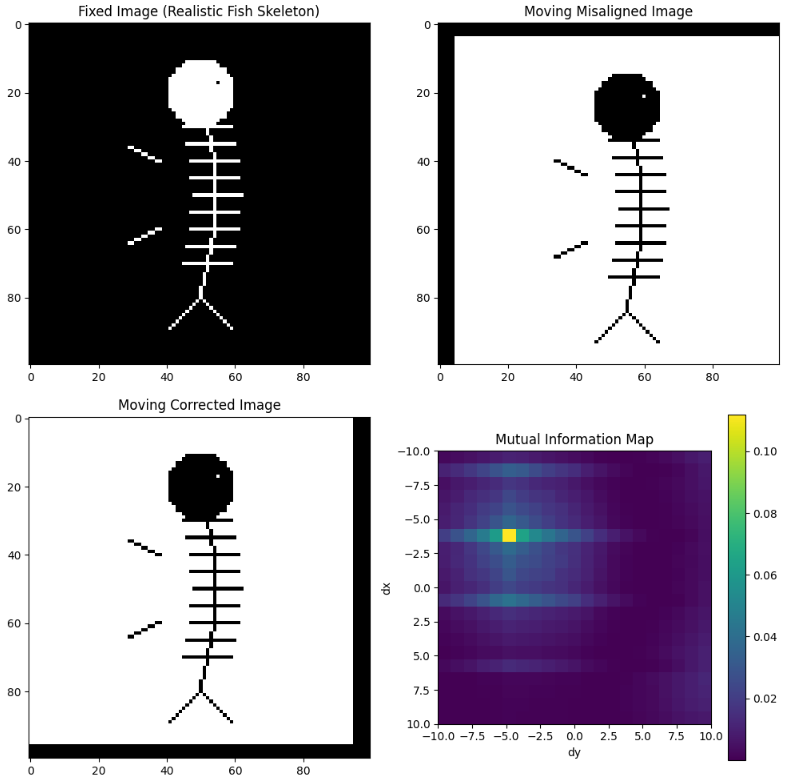
print(f"Best shift: dx = {best_dx}, dy = {best_dy}")
# Apply best shift
moving_corrected = shift_image(moving_misaligned, best_dx, best_dy)
# Plot
fig, axs = plt.subplots(2, 2, figsize=(10,10))
axs[0,0].imshow(fixed, cmap='gray')
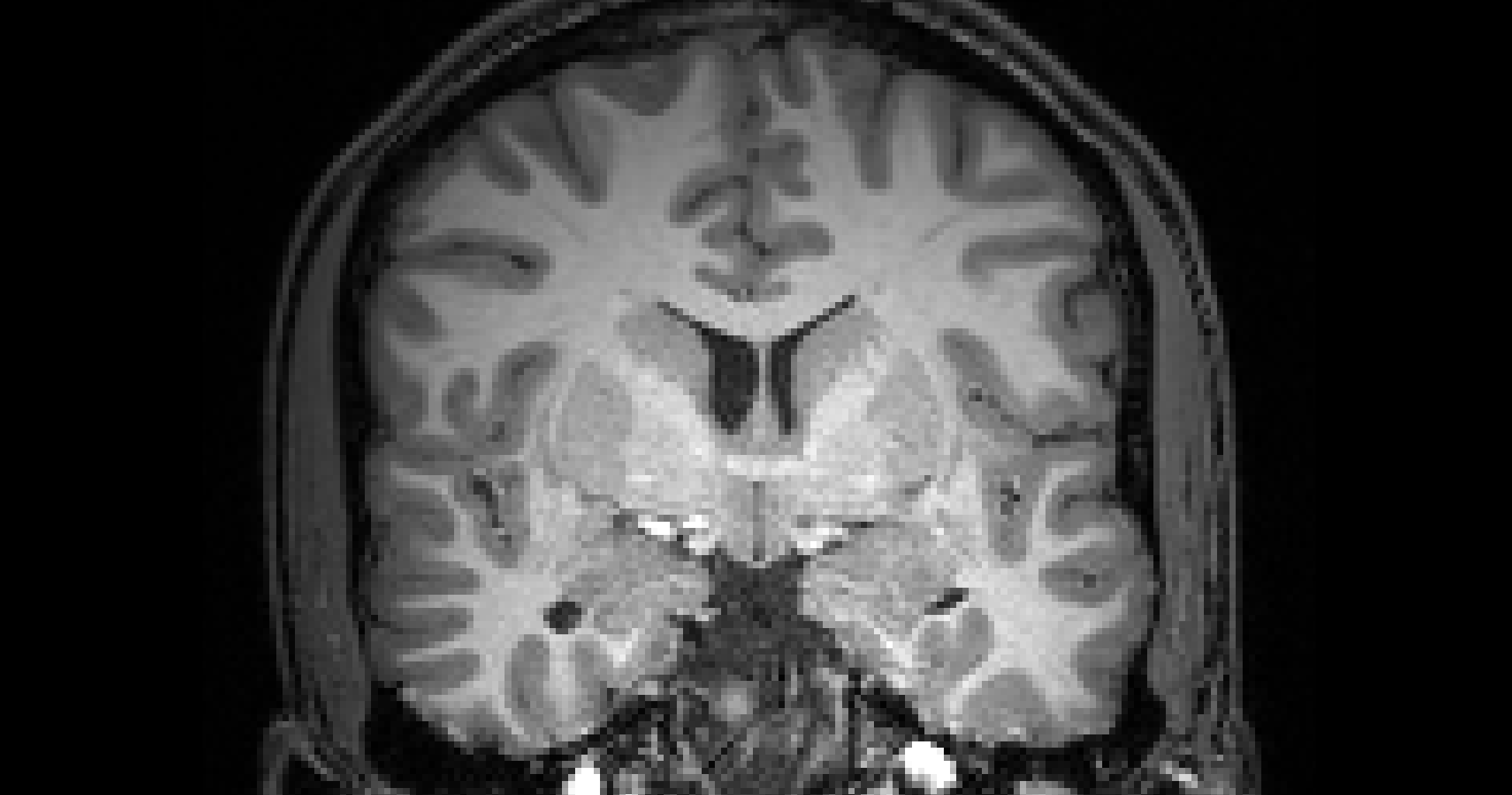
axs[0,0].set_title('Fixed Image (Realistic Fish Skeleton)')
axs[0,1].imshow(moving_misaligned, cmap='gray')
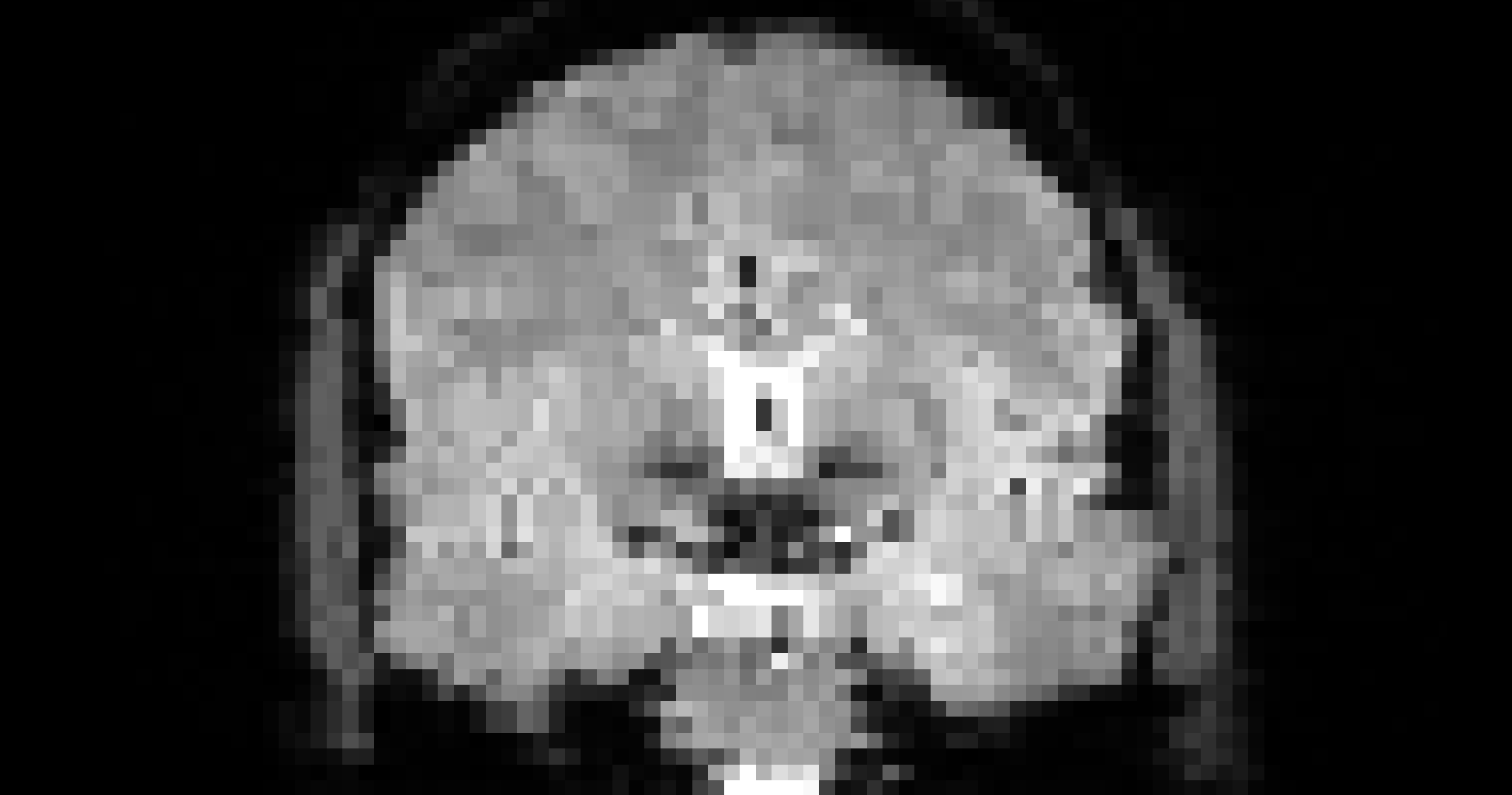
axs[0,1].set_title('Moving Misaligned Image')
axs[1,0].imshow(moving_corrected, cmap='gray')
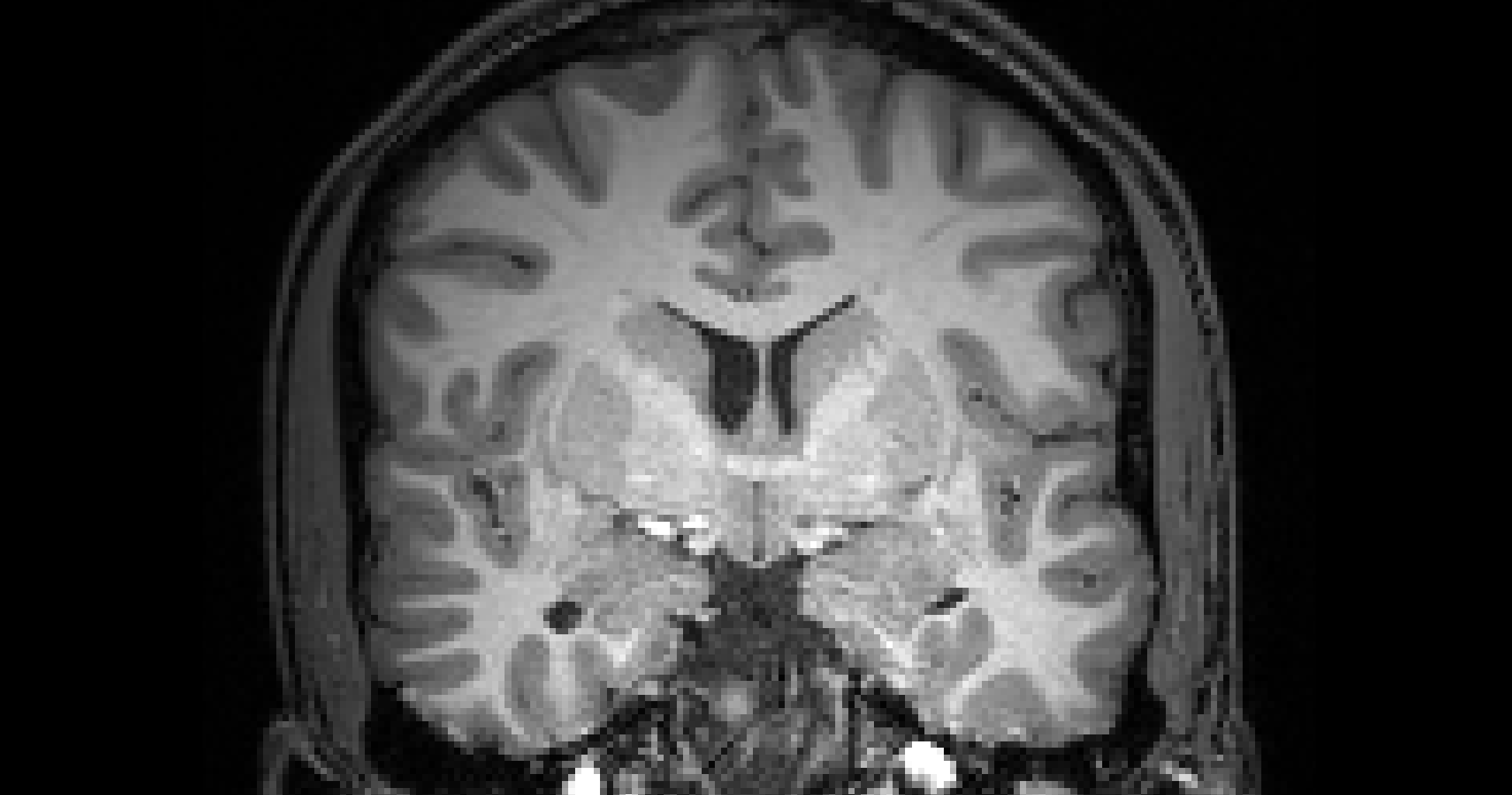
axs[1,0].set_title('Moving Corrected Image')
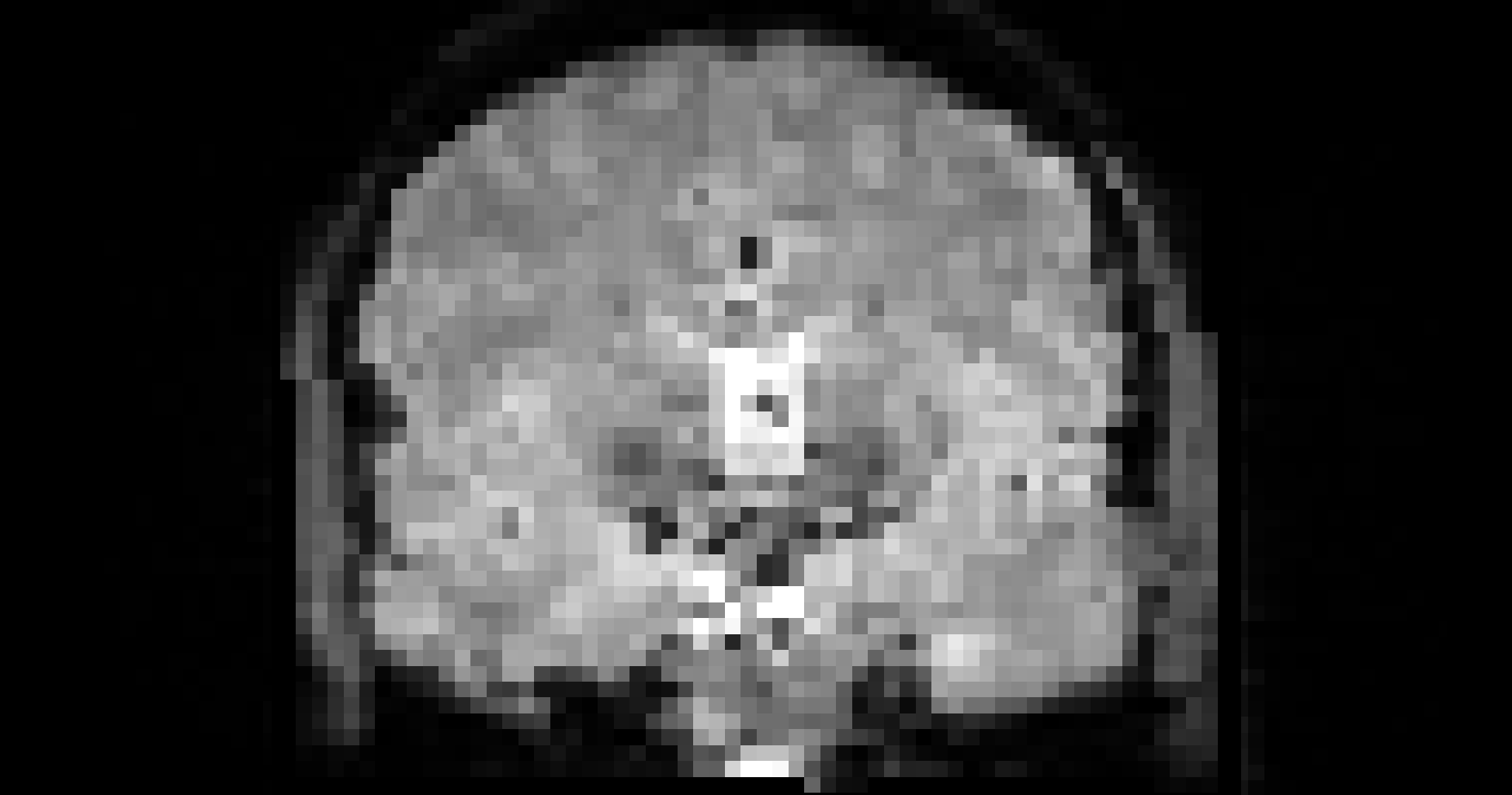
cax = axs[1,1].imshow(mi_matrix, extent=[dy_range[0], dy_range[-1], dx_range[-1], dx_range[0]], cmap='viridis')
axs[1,1].set_title('Mutual Information Map')
axs[1,1].set_xlabel('dy')
axs[1,1].set_ylabel('dx')
fig.colorbar(cax, ax=axs[1,1])
plt.tight_layout()
plt.show()